
How Cursor Indexes Codebases Fast
Merkle Trees in the real world

Engineer’s Codex is a publication about real-world software engineering.
Cursor, the popular AI IDE that recently announced they hit $300M ARR, uses Merkle trees to index code fast. This post goes over exactly how.
Before diving into Cursor's implementation, let's first understand what a Merkle tree is.
Merkle Trees Explained Simply
A Merkle tree is a tree structure in which every "leaf" node is labeled with the cryptographic hash of a data block, and every non-leaf node is labeled with the cryptographic hash of the labels of its child nodes. This creates a hierarchical structure where changes at any level can be efficiently detected by comparing hash values.
Think of them as a fingerprinting system for data:
Each piece of data (like a file) gets its own unique fingerprint (hash)
Pairs of fingerprints are combined and given a new fingerprint
This process continues until you have just one master fingerprint (the root hash)
The root hash summarizes all data contained in the individual pieces, serving as a cryptographic commitment to the entire dataset. The beauty of this approach is that if any single piece of data changes, it will change all the fingerprints above it, ultimately changing the root hash.

SWE Quiz (Sponsored)
Top software engineers know a lot. But how do you know what you don’t know?
SWE Quiz is a platform with roadmaps on system design fundamentals, like API design, databases, and more. There are three roadmaps launching in June: distributed systems, LLM fundamentals, and a React interview roadmap.
Get lifetime access to SWE Quiz, used by devs who have used the platform to get into companies like Google, Meta, and Airbnb.
How Cursor Uses Merkle Trees for Codebase Indexing
Cursor uses Merkle trees as a core component of its codebase indexing feature. According to a post by Cursor's founder and the security documentation, here's how it works:
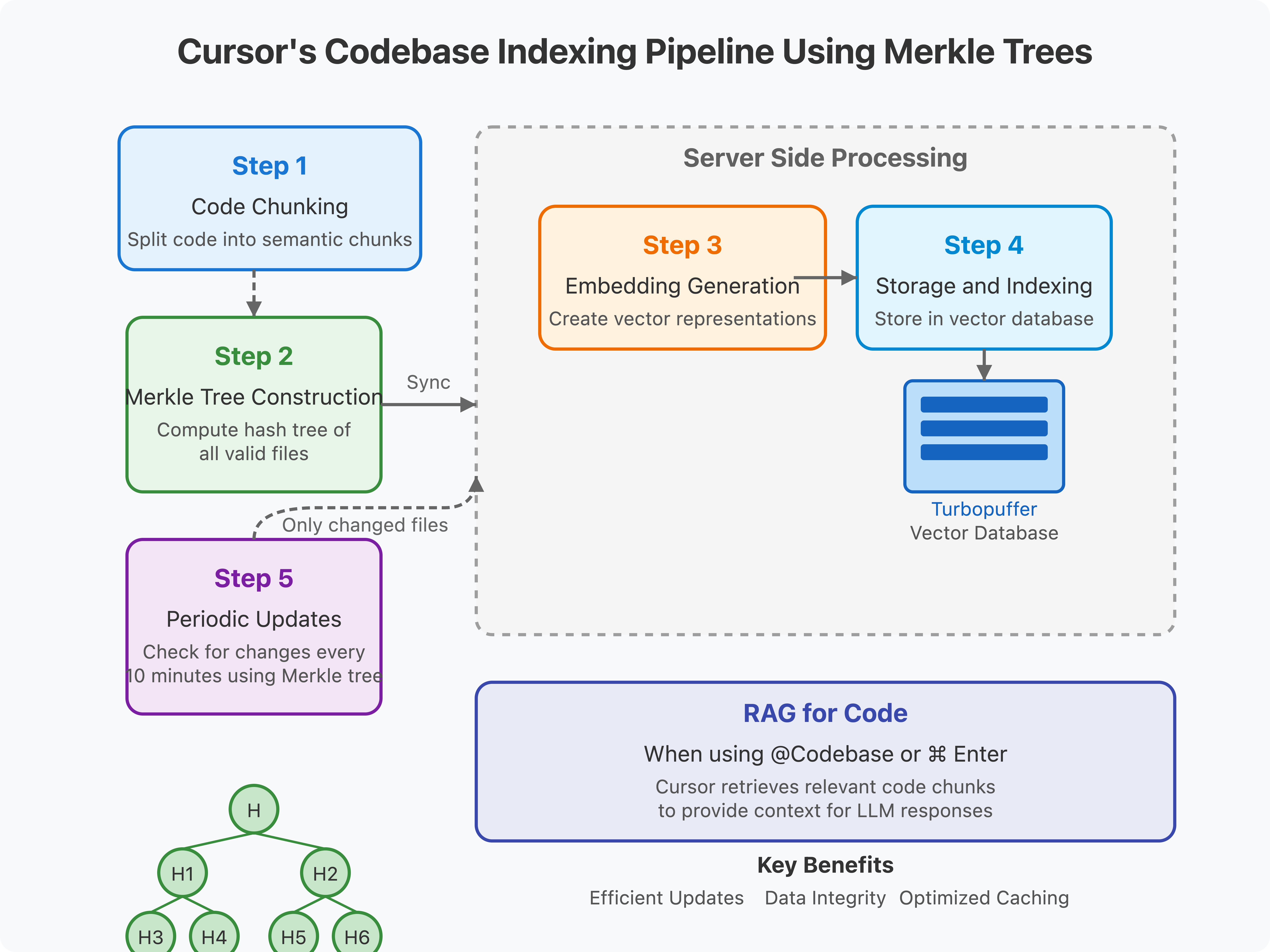
Step 1: Code Chunking and Processing
Cursor first chunks your codebase files locally, splitting code into semantically meaningful pieces before any processing occurs.
Step 2: Merkle Tree Construction and Synchronization
When codebase indexing is enabled, Cursor scans the folder opened in the editor and computes a Merkle tree of hashes of all valid files. This Merkle tree is then synchronized with Cursor's server, as detailed in Cursor's security documentation.
Step 3: Embedding Generation
After the chunks are sent to Cursor's server, embeddings are created using either OpenAI's embedding API or a custom embedding model (I couldn’t verify this). These vector representations capture the semantic meaning of the code chunks.
Step 4: Storage and Indexing
The embeddings, along with metadata like start/end line numbers and file paths, are stored in a remote vector database (Turbopuffer). To maintain privacy while still enabling path-based filtering, Cursor stores an obfuscated relative file path with each vector. Importantly, according to Cursor's founder, "None of your code is stored in our databases. It's gone after the life of the request."
Step 5: Periodic Updates Using Merkle Trees
Every 10 minutes, Cursor checks for hash mismatches, using the Merkle tree to identify which files have changed. Only the changed files need to be uploaded, significantly reducing bandwidth usage, as explained in Cursor's security documentation. This is where the Merkle tree structure provides its greatest value—enabling efficient incremental updates.
Code Chunking Strategies
The effectiveness of the codebase indexing largely depends on how code is chunked. While my previous explanation didn't go into detail about chunking methods, this blog post about building a Cursor-like codebase feature provides some insights:
While simple approaches split code by characters, words, or lines, they often miss semantic boundaries—resulting in degraded embedding quality.
You can split code based on a fixed token count, but this can cut off code blocks like functions or classes mid-way.
A more effective approach is to use an intelligent splitter that understands code structure, such as recursive text splitters that use high-level delimiters (e.g., class and function definitions) to split at appropriate semantic boundaries.
An even more elegant solution is to split the code based on its Abstract Syntax Tree (AST) structure. By traversing the AST depth-first, it splits code into sub-trees that fit within token limits. To avoid creating too many small chunks, sibling nodes are merged into larger chunks as long as they stay under the token limit. Tools like tree-sitter can be used for this AST parsing, supporting a wide range of programming languages.
For a crash course on tokens, read this.
How Embeddings Are Used at Inference Time
After covering how Cursor creates and stores code embeddings, a natural question arises: how are these embeddings actually used once they've been generated? This section explains the practical application of these embeddings during normal usage.
Semantic Search and Context Retrieval
When you interact with Cursor's AI features like asking questions about your codebase (using @Codebase or ⌘ Enter), the following process occurs:
Query Embedding: Cursor computes an embedding for your question or the code context you're working with.
Vector Similarity Search: This query embedding is sent to Turbopuffer (Cursor's vector database), which performs a nearest-neighbor search to find code chunks semantically similar to your query.
Local File Access: Cursor's client receives the results, which include obfuscated file paths and line ranges of the most relevant code chunks. Importantly, the actual code content remains on your machine and is retrieved locally.
Context Assembly: The client reads these relevant code chunks from your local files and sends them as context to the server for the LLM to process alongside your question.
Informed Response: The LLM now has the necessary context from your codebase to provide a more informed and relevant response to your question or to generate appropriate code completions.
This embedding-powered retrieval allows for:
Contextual Code Generation: When writing new code, Cursor can reference similar implementations in your existing codebase, maintaining consistent patterns and styles.
Codebase Q&A: You can ask questions about your codebase and get answers informed by your actual code rather than generic responses.
Smart Code Completion: Code completions can be enhanced with awareness of your project's specific conventions and patterns.
Intelligent Refactoring: When refactoring code, the system can identify all related pieces across your codebase that might need similar changes.
Why Cursor Uses Merkle Trees
Many of these details are security-related, and thus can be found in Cursor’s security documentation.
1. Efficient Incremental Updates
By using a Merkle tree, Cursor can quickly identify exactly which files have changed since the last synchronization. Instead of re-uploading the entire codebase, it only needs to upload the specific files that have been modified. This is important for large codebases where re-indexing everything would be too expensive in terms of bandwidth and processing time.
2. Data Integrity Verification
The Merkle tree structure allows Cursor to efficiently verify that the files being indexed match what's stored on the server. The hierarchical hash structure makes it easy to detect any inconsistencies or corrupted data during transfer.
3. Optimized Caching
Cursor stores embeddings in a cache indexed by the hash of the chunk, ensuring that indexing the same codebase a second time is much faster. This is great for teams where multiple developers might be working with the same codebase.
4. Privacy-Preserving Indexing
To protect sensitive information in file paths, Cursor implements path obfuscation by splitting the path by '/' and '.' characters and encrypting each segment with a secret key stored on the client. While this still reveals some information about directory hierarchy, it hides most sensitive details.
5. Git History Integration
When codebase indexing is enabled in a Git repository, Cursor also indexes the Git history. It stores commit SHAs, parent information, and obfuscated file names. To enable sharing the data structure for users in the same Git repo and on the same team, the secret key for obfuscating file names is derived from hashes of recent commit contents.
Embedding Models and Considerations
The choice of embedding model significantly impacts the quality of code search and understanding. While some systems use open-source models like all-MiniLM-L6-v2, Cursor likely uses either OpenAI's embedding models or custom embedding models specifically tuned for code. For specialized code embeddings, models like Microsoft's unixcoder-base or Voyage AI's voyage-code-2 are good for code-specific semantic understanding.
The embedding challenge is made more complex because embedding models have token limits. OpenAI's text-embedding-3-small model, for example, has a token limit of 8192. Effective chunking helps stay within token limits while preserving semantic meaning.
The Handshake Process
A key aspect of Cursor's Merkle tree implementation is the handshake process that occurs during synchronization. Logs from the Cursor application reveal that when initializing codebase indexing, Cursor creates a "merkle client" and performs a "startup handshake" with the server. This handshake involves sending the root hash of the locally computed Merkle tree to the server, as seen in Issue #2209 on GitHub and Issue #981 on GitHub.
The handshake process allows the server to determine which parts of the codebase need to be synced. Based on the handshake logs, we can see that Cursor computes the initial hash of the codebase and sends it to the server for verification, as documented in Issue #2209 on GitHub.
Technical Implementation Challenges
While the Merkle tree approach offers many advantages, it's not without implementation challenges. Cursor's indexing feature often experiences heavy load, causing many requests to fail. This can result in files needing to be uploaded several times before they get fully indexed. Users might notice higher than expected network traffic to 'repo42.cursor.sh' as a result of these retry mechanisms, as mentioned in Cursor's security documentation.
Another challenge relates to embedding security. Academic research has shown that reversing embeddings is possible in some cases. While current attacks typically rely on having access to the embedding model and working with short strings, there is a potential risk that an adversary who gains access to Cursor's vector database could extract information about indexed codebases from the stored embeddings.
This was interesting to learn more about. It seems like an application of the fundamentals of web crawling for example and its inverted index table, where searching each word/token could leave to the files containing said word
They use the same approach with Merkle trees as in the original - git. Not reinventing the wheel when tracking the code changes is absolutely reasonable