
How Instagram scaled to 14 million users with only 3 engineers
Instagram's guiding principles and tech stack explained simply
Author’s Note: This is a timeline of notes compiled from publicly available sources. All links and sources are posted at the bottom, and throughout.
Instagram scaled from 0 to 14 million users in just over a year, from October 2010 to December 2011. They did this with only 3 engineers.
They did this by following 3 key principles and having a reliable tech stack.
Instagram’s Guiding Principles
Keep things very simple.
Don’t re-invent the wheel.
Use proven, solid technologies when possible.
Before I continue… I want to introduce SWE Quiz.
It’s a resource of 450+ questions to reveal your gaps in software domain knowledge, like databases, caching, and networking. It’s perfect to feel more confident at work or brush up on knowledge before interviews.
It’s one lifetime purchase with lifetime updates included.
The Stack Explained Simply
Early Instagram’s infrastructure ran on AWS, using EC2 with Ubuntu Linux. For reference, EC2 is Amazon’s service that allows developers to rent virtual computers.
To make things easy, and since I like thinking about the user from an engineer’s perspective, let’s go through the life of a user session. (Marked with Session:)
Frontend
Session: A user opens the Instagram app.
Instagram initially launched as an iOS app in 2010. Since Swift was released in 2014, we can assume that Instagram was written using Objective-C and a combination of other things like UIKit.

Load Balancing
Session: After opening the app, a request to grab the main feed photos is sent to the backend, where it hits Instagram’s load balancer.
Instagram used Amazon’s Elastic Load Balancer. They had 3 NGINX instances that were swapped in and out depending on if they were healthy.
Each request hit the load balancer first before being routed to the actual application server.

Backend
Session: The load balancer sends the request to the application server, which holds the logic to process the request correctly.
Instagram’s application server used Django and it was written in Python, with Gunicorn as their WSGI server.
As a refresher, a WSGI (Web Server Gateway Interface) forwards requests from a web server to a web application.
Instagram use Fabric to run commands in parallel on many instances at once. This allows to deploy code in just seconds.
These lived on over 25 Amazon High-CPU Extra-Large machines. Since the server itself is stateless, when they needed to handle more requests, they could add more machines.
General Data Storage
Session: The application server sees that the request needs data for the main feed. For this, let’s say it needs:
latest relevant photo IDsthe actual photos that match those photo IDsuser data for those photos.
Database: Postgres
Session: The application server grabs the latest relevant photo IDs from Postgres.
The application server would pull data from PostgreSQL, which stored most of Instagram’s data, such as users and photo metadata.
The connections between Postgres and Django were pooled using Pgbouncer.
Instagram sharded their data because of the volume they were receiving (over 25 photos and 90 likes a second). They used code to map several thousand ‘logical’ shards to a few physical shards.
An interesting challenge that Instagram faced and solved is generating IDs that could be sorted by time. Their resulting sortable-by-time IDs looked like this:
41 bits for time in milliseconds (gives us 41 years of IDs with a custom epoch)
13 bits that represent the logical shard ID
10 bits that represent an auto-incrementing sequence, modulus 1024. This means we can generate 1024 IDs, per shard, per millisecond
(You can read more here.)
Thanks to the sortable-by-time IDs in Postgres, the application server has successfully received the latest relevant photo IDs.
Photo Storage: S3 and Cloudfront
Session: The application server then gets the actual photos that match those photo IDs with fast CDN links so that they load fast for the user.
Several terabytes of photos were stored in Amazon S3. These photos were served to users quickly using Amazon CloudFront.
Caching: Redis and Memcached
Session: To get the user data from Postgres, the application server (Django) matches photo IDs to user IDs using Redis.
Instagram used Redis to store a mapping of about 300 million photos to the user ID that created them, in order to know which shard to query when getting photos for the main feed, activity feed, etc. All of Redis was stored in-memory to decrease latency and it was sharded across multiple machines.
With some clever hashing, Instagram was able to store 300 million key mappings in less than 5 GB.
This photoID to user ID key-value mapping was needed in order to know which Postgres shard to query.
Session: Thanks to efficient caching using Memcached, getting user data from Postgres was fast since the response was recently cached.
For general caching, Instagram used Memcached. They had 6 Memcached instances at the time. Memcached is relatively simple to layer over Django.
Interesting fact: 2 years later, in 2013, Facebook released a landmark paper on how they scaled Memcached to help them handle billions of requests per second.
Session: The user now sees the home feed, populated with the latest pictures from people he is following.

Master-Replica Setup
Both Postgres and Redis ran in a master-replica setup and used Amazon EBS (Elastic Block Store) snapshotting to take frequent backups of the systems.
Push Notifications and Async Tasks
Session: Now, let’s say the user closes the app, but then gets a push notification that a friend posted a photo.
This push notification was sent using pyapns, along with the billion+ other push notifications Instagram had sent out already. Pyapns is an open-source, universal Apple Push Notification Service (APNS) provider.
Session: The user really liked this photo! So he decided to share it on Twitter.
On the backend, the task is pushed into Gearman, a task queue which farmed out work to better-suited machines. Instagram had ~200 Python workers consuming the Gearman task queue.
Gearman was used for multiple asynchronous tasks, like pushing out activities (like a new photo posted) to all of a user’s followers (this is called fanout).

Monitoring
Session: Uh oh! The Instagram app crashed because something erred on the server and sent an erroneous response. The three Instagram engineers get alerted instantly.
Instagram used Sentry, an open-source Django app, to monitor Python errors in real-time.
Munin was used to graph system-wide metrics and alert anomalies. Instagram had a bunch of custom Munin plugins to track application-level metrics, like photos posted per second.
Pingdom was used for external service monitoring and PagerDuty was used for handling incidents and notifications.
Final Architecture Overview
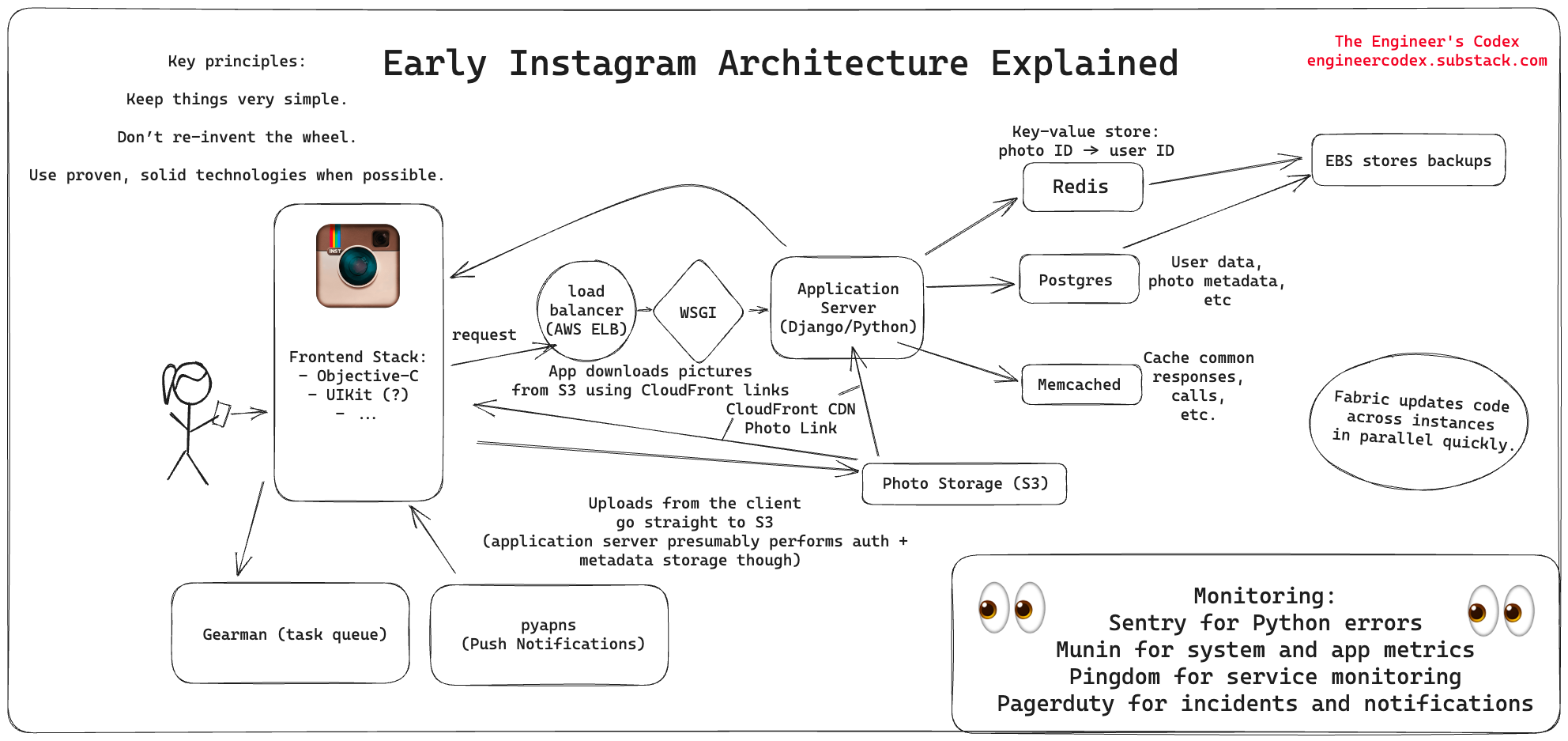
Sources:
This was a really nice read that helps really solidify some system design theoretical concepts seeing how it's applied in the real-world.
I also appreciated the diagram at the end too to help piece it all together.
Thanks for the article!
Thank you for this convenient post!
About the S3 uploads, they cannot go direct to AWS servers. It has to go through the Instagram servers since the upload needs to be authenticated AND the S3 connection secrets can/should not be kept on the client end.