
How to Write "Garbage Code" (by Linus Torvalds)
Linus Torvalds, Creator of Git and Linux, on reducing cognitive load

Engineer’s Codex is a newsletter about becoming a better engineer and clearer thinker through timeless engineering ideas.
Recently, Linus Torvalds, the creator of Git and Linux, berated a Meta engineer on a PR they made recently.
“No. This is garbage and it came in too late. I asked for early pull requests because I'm traveling, and if you can't follow that rule, at least make the pull requests good.
This adds various garbage that isn't RISC-V specific to generic header files.
And by "garbage" I really mean it. This is stuff that nobody should ever send me, never mind late in a merge window.
Like this crazy and pointless make_u32_from_two_u16() "helper".
That thing makes the world actively a worse place to live. It's useless garbage that makes any user incomprehensible, and actively WORSE than not using that stupid "helper".
If you write the code out as "(a << 16) + b", you know what it does and which is the high word. Maybe you need to add a cast to make sure that 'b' doesn't have high bits that pollutes the end result, so maybe it's not going to be exactly pretty, but it's not going to be wrong and incomprehensible either.
In contrast, if you write make_u32_from_two_u16(a,b) you have not a f^%$ing clue what the word order is. IOW, you just made things WORSE, and you added that "helper" to a generic non-RISC-V file where people are apparently supposed to use it to make other code worse too.
So no. Things like this need to get bent. It does not go into generic header files, and it damn well does not happen late in the merge window.”
(Disregarding the fact that this pull request was sent in way too late, I agree)
I think this is a good example of “Write Everything Twice” or “Yes, Please Repeat Yourself”, as I’ve written about before.
Now that we have coding agents that are much better, I think the PRY principle here actually is more important than before.
But the main point Linus makes here is that good code optimizes for reducing cognitive load.
Reducing Micro-Context Switches
Today, code now has multiple readers: computers, LLMs, and software engineers.
Humans and LLMs have a limited amount of context they can store in their “context window” at a time. Having to go to a new file or function to understand it requires a slight context switch and requires extra brainpower (and tokens) to absorb that new information. An LLM now has to understand a new file, a new path, a new extra function. So, a function that uses 0 helper functions throughout requires less context and brainpower than a function with 5 helper functions.
Neuroscience shows switching tasks incurs measurable brain energy costs. Jumping across files is a micro–context switch. The more helpers/abstractions, the more “switch costs” pile up.
Humans have limited working memory capacity - let’s say the human brain can only store 4-7 “chunks” at at time. Each abstraction or helper function costs a chunk slot. Each abstractions costs more tokens. Too many layers means cognitive overload. Too many tokens used means a higher chance of error.
This means that sometimes, duplication is actually reducing cognitive load, because the “chunk” is self-contained.
Sometimes, of course, it’s justified to have abstracted components and functions. For example, if you want to enforce a certain behavior across your codebase, a helper function is probably a good thing.
On the other hand, it’s fine to have reused code throughout for simple operations, even if reused. Do you really need that helper file or abstracted class?
In fact, it makes code clearer, easier to understand, and most importantly, easier to iterate on. It’s much easier to point Claude Code or Codex to one file and ask it to make changes, rather than needing to DFS through 3-4 different files to fully understand the context of the “parent” file.
In performance engineering, “locality of reference” (keeping data/code close together) is necessary for efficiency. PRY is like a cognitive locality of reference.
Last, but not least, the cost of premature optimization has never been higher, especially in a world where, with modern IDEs and LLMs, code is cheaper to refactor than ever. The cost of duplication has dropped and will continue dropping moving forward.
It doesn’t cost anything to be nice
One thing to not take from Linus’s point: the tone and general rudeness. Everyone works differently, obviously, but being nicer never hurts :).
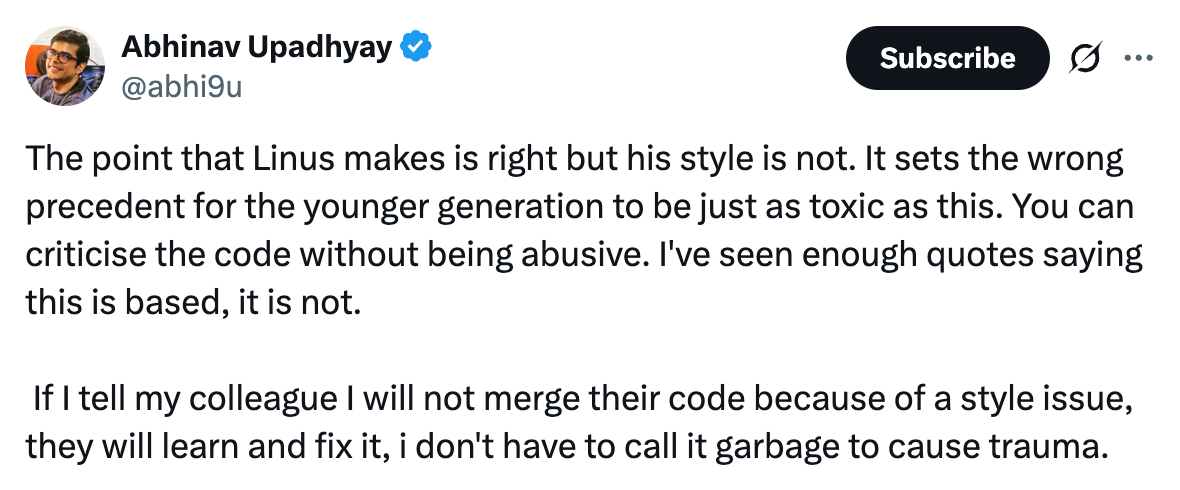
Being rude makes committing code a risk. Nobody wants to write code and risk the chance of being berated publicly like above. Abhinav put it well here:
> duplication is actually reducing cognitive load, because the “chunk” is self-contained
I've been thinking about that and I'm still not convinced. In my experience most of the time duplicate code increases cognitive load because every time I suspect a block of code is duplicate I have to go back and check if the other duplicate places do exactly the same thing or something slightly different. Just as DRY can be abused, PRY will be as well, and I'm afraid the consequences will be worse than the consequences of DRY abuse.
> One thing to not take from Linus’s point: the tone and general rudeness.
Yeah, beat me to it. I've seen him have other outbursts in the past, and frankly it's disappointing. I'm not involved with the Linux project, but if I was, I'd be sure to avoid him because of behavior like this.
Dude needs to be kind and rewind.