
Metric-Driven Development and The Claude Effect
Sometimes, feels have to be trusted over figures

Engineer’s Codex is a publication about real-world software engineering.
Anthropic, in their release of Claude 3.7 and Claude Code, wrote:
"…in developing our reasoning models, we've optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect how businesses actually use LLMs. Early testing demonstrated Claude's leadership in coding capabilities across the board: Cursor noted Claude is once again best-in-class for real-world coding tasks, with significant improvements in areas ranging from handling complex codebases to advanced tool use."
It immediately reminded me of a Jeff Bezos quote from an interview he had:
"When the data and the anecdotes disagree, the anecdotes are usually right. It's usually not that the data is being miscollected. It's usually that you're not measuring the right thing. If you have a bunch of customers complaining about something, and at the same time your metrics look like they shouldn't be complaining, you should doubt the metrics." The full quote is great.
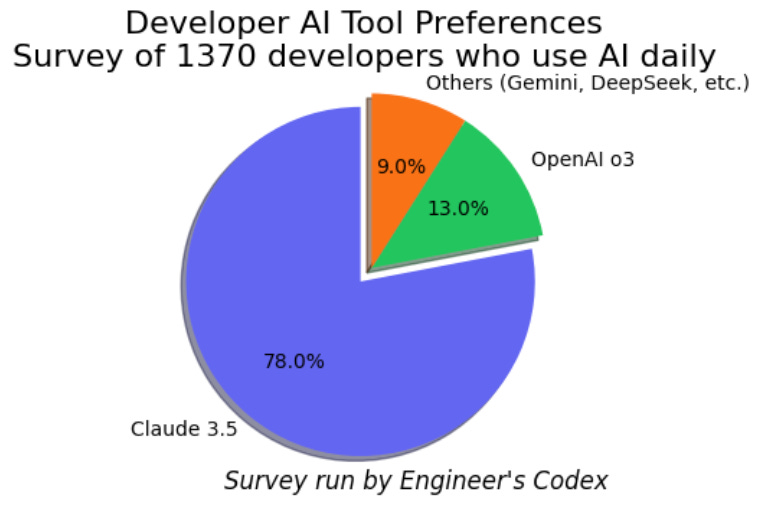
Developers who have used all the popular AI tools (ChatGPT, Claude, etc), generally prefer Claude for coding over the rest. I recently ran a survey on developers wh
Though we have Google's Gemini and OpenAI's models topping the AI leaderboards in terms of benchmarks, Claude still remains the best coding tool in terms of the real world. (Yes, I know the benchmark for this is technically SWE-Bench). There's a reason why it's the default model for popular AI IDEs like Windsurf - no matter what the benchmarks say, there's a certain "vibe" to Claude that ends up passing for devs compared to the other models.
Devs prefer Claude in the real world
I recently ran a survey with 1370 devs who use AI often (at least once a day) during coding.
A vast majority of them preferred Claude 3.5 over any other:
78% preferred Claude 3.5 as their #1 choice
13% chose OpenAI's o3 models
9% used other models, like Gemini
This isn't isolated to AI tools. As one developer noted on Hacker News:
"Claude is the best example of benchmarks not being reflective of reality. All the AI labs are so focused on improving benchmark scores but when it comes to providing actual utility Claude has been the winner for quite some time. Which isn't to say that benchmarks aren't useful. They surely are. But labs are clearly both overtraining and overindexing on benchmarks."
SWE Quiz (Sponsored)
SWE Quiz is the easiest way to build your system design fundamentals through 500+ questions on concepts like authentication, databases, and more.
SWE Quiz has crash courses to get up to speed quickly, smart quizzes to fill in gaps of knowledge, interview readiness scores, and concept roadmaps. It is offering a lifetime payment for a limited time and new content is being added weekly.
Metric-driven development can be a problem
When metrics become the goal rather than a tool for measurement, we enter dangerous territory. At its core, metric-driven development is meant to provide objective guidance for improvement. But too often, it creates a myopic focus that misses the forest for the trees. This is especially true for large FAANG-level companies, where the size of the company and incentives for rewards like promotion are usually numbers-based. Launching a half-baked feature/product to millions of pre-existing mobile DAUs lets you say “you gained millions of DAUs” on your promotion packet, regardless of whether the product is even liked by users or not. After that, it commonly becomes someone else’s problem to find a metric that correlates with how much users like the product and then work towards improving it.
“A Harvard Business Review article looked at Wells Fargo as a case study of how letting metrics replace strategy can harm a business. After identifying cross-selling as a measure of long-term customer relationships, Wells Fargo went overboard emphasizing the cross-selling metric: intense pressure on employees combined with an unethical sales culture led to 3.5 million fraudulent deposit and credit card accounts being opened without customers' consent. The metric of cross-selling is a much more short-term concern compared to the loftier goal of nurturing long-term customer relationships.” - Data.Blog
This pattern repeats in tech companies of all sizes. A developer from a FAANG company shared this revealing story:
"At <FAANG mega-corp>, I used to work on an internal team which basically did nothing important, certainly nothing users ever think about. The problem that we were trying to solve, well, we had already solved it about 3 years ago, yet the team was still expanding, and our product managers kept spitting out new (mostly useless) project ideas. One of the main areas of focus was metrics. Leadership was obsessed with metrics, we measured everything."
The contrast came when this developer moved to a smaller team with a clearer purpose:
"One of the first things I said to my new product manager was 'so, what metrics do you care about? how do you measure success?' He was taken aback by my question. He seemed genuinely perplexed. He paused for a few seconds, then said 'metrics? What do you mean by metrics? I look at revenue, when the line goes up I'm happy'."
This simplicity - focusing on actual outcomes rather than proxy measurements - cuts to the heart of the problem with pure metric-driven development.
Feels Over Figures, Vibes Equals Value
What's happening with Claude is something I’ve been casually calling “Feels over Figures” - when a tool's real-world feedback doesn’t necessarily match its overall benchmark performance. Yes, Claude does dominate SWE-bench, but in general, Claude has won over users because it delivers what they actually need in their workflow.
“The Claude Effect” here shows what’s missing - the human element, the "feel" of using a tool, and the general vibes of using a tool.
I suspect this is also why OpenAI chose to release GPT-4.5, which from a practical numbers perspective, doesn’t really make sense at all. It’s seemingly worse numbers wise on so many things, like reasoning and price. But they specifically denote the “EQ” of the model, which is presumably the optimization that they are hill climbing for here. If they’re going to take a note from DeepSeek, they’ll probably use GPT-4.5 to increase the EQ of the rest of their models.
If anything, especially when working on something as non-deterministic as LLMs, it makes sense to accept that there is extra human toil necessary to understand the “vibes” aspect when evaluating performance. This means having more human spot checks and collecting more valuable human qualitative feedback (and not necessarily grinding it down to a number or throwing it onto a Likert scale immediately). It also means prioritizing the non-technical aspects too - like design and user flows.
The gap between metrics and real-world value isn't going away, so rather, it's best to have methods to bridge them as close as possible. The Claude Effect teaches us that sometimes the most valuable aspects of a tool come from qualities that aren't easily quantified - the intuitiveness of its responses, how well it aligns with developer thinking patterns, or how seamlessly it fits into existing workflows.
One Hacker News commenter put it as the "gamedev mindset": "Yes data is good. But I think the industry would very often be better off trusting guts and not needing a big huge expensive UX study or benchmark to prove what you can plainly see."