
How Apple built iCloud to store billions of databases
Apple uses Cassandra and FoundationDB for CloudKit, their cloud backend service. We take a look into how exactly each is used within their cloud and the problems they've solved.
Engineer’s Codex is a publication distilling real-world software engineering.
Author’s Note: These are my personal notes on publicly available papers regarding iCloud. All sources are linked at the bottom.
Throughout the last few months, I’ve written about various tech “behind-the-scenes” in Big Tech, such as Meta's internal serverless platform, that we are lucky to see written about publicly.
Apple, on the other hand, is not as public with their infrastructure. I wanted to find out how Apple built iCloud and in this article, I cover everything I know.
Apple uses FoundationDB and Cassandra for iCloud and CloudKit, their cloud backend service. And yes, the title is not incorrect: Apple really does store billions of databases in their extreme multi-tenant architecture.
Timeless Real-World Lessons
Before reading, these are the applicable lessons and guidelines.
I found that a lot of the lessons from the paper and from Apple track very closely to the lessons of Meta’s architecture of their serverless platform.
Both use asynchronous processing smartly in order to make user functionalities smoother. Meta uses their serverless stack for non-user-facing functions. Apple uses async processing for almost all of the Record Layer’s functionalities (explained in-depth down below) in order to hide latency from the user.
Both utilize stateless architecture liberally, knowing that they have intense scalability needs.
Both isolate resources logically for reliability and availability.
Both handle diverse ranges of needs simply. Apple mentions how it’s “tempting
to provision and operate separate systems to store ‘small data’ and ‘big data.’” However, this increases operational complexity, and instead, they handle all types of data needs with one abstraction. Meta does the same with their serverless platform providing one abstraction for all kinds of function loads.
Both build layers of abstractions in order to make the developer experience better. Application developers shouldn’t have to worry about scalability needs - that’s handled deeper down the stack by distributed system engineers.
Know your user. Each layer, API, and design decision provided by Meta and Apple is guided by clear knowledge on who the user of the specific technology is, whether it be an application development team or an observability team.
Cassandra
Cassandra is a wide-column NoSQL database management system. It was originally developed at Facebook to power the Facebook inbox search feature. Interestingly, Meta themselves have replaced much of their Cassandra usage with ZippyDB instead.
iCloud is partly powered by Cassandra. Apple runs one of the largest Cassandra deployments in the world, according to DataStax.
Over 300k instances/nodes
Hundreds of petabytes of data (if not exabytes)
Over 2 PB per cluster, with thousands of clusters
Millions of queries per second
Thousands of applications

Other snippets of Cassandra in iCloud show that there are exabytes of data under management. There are multiple Cassandra nodes per server, and the teams at Apple are smart about blast radius and sharding. This makes sure iCloud data availability is near 100%.
Cassandra is still actively improved upon at Apple. Scott Andreas of Apple gave a talk about the future of Cassandra last month. On Apple’s jobs page, they commonly mention Cassandra when hiring for distributed systems engineers.
However, CloudKit + Cassandra ran into two scalability limitations, which led to their adoption of FoundationDB.
Within a single zone, only one operation can happen at a time, even if different records are being edited. This can be problematic for apps where multiple users or devices need to work on shared data simultaneously.
When updating multiple records simultaneously in an atomic operation, the updates are limited to a single Cassandra partition. These partitions have a maximum size they can handle, and as a partition's size increases, Cassandra tends to slow down.
FoundationDB and the Record Layer solved both of these issues.
FoundationDB
Apple is much more public about FoundationDB. They acquired FoundationDB in 2015 and have since published various papers detailing their use of FoundationDB.
FoundationDB is an open-source, distributed, transactional key-value store. It’s designed to handle large volumes of data and works well for both read/write workloads and write-heavy workloads. It’s also ACID-compliant.
Apple uses the FoundationDB Record Layer extensively for CloudKit (Apple’s cloud backend service).

From their GitHub:
The Record Layer is a Java API providing a record-oriented store on top of FoundationDB, (very) roughly equivalent to a simple relational database, featuring:
Structured types - Records are defined and stored in terms of protobuf (Protocol Buffer) messages. Protocol Buffers were first designed by Google.
Indexes - The Record Layer supports a variety of different index types including value indexes (the kind provided by most databases), rank indexes, and aggregate indexes. Indexes and primary keys can be defined either via protobuf options or programmatically.
Complex types - Support for complex types, such as lists and nested records, including the ability to define indexes against such nested structures.
Queries - The Record Layer does not provide a query language, however it provides query APIs with the ability to scan, filter, and sort across one or more record types, and a query planner capable of automatic selection of indexes.
Many record stores, shared schema - The Record Layer provides the ability to support many discrete record store instances, all with a shared (and evolving) schema. For example, rather than modeling a single database in which to store all users' data, each user can be given their own record store, perhaps sharded across different FDB cluster instances.
Very light weight - The Record layer is designed to be used in a large, distributed, stateless environment. The time between opening a store and the first query is intended to be measured in milliseconds.
Extensible - New index types and custom index key expressions may be dynamically incorporated into a record store.
From the FoundationDB Record Layer paper, they write:
“[FoundationDB Record Layer is used] to provide powerful abstractions to applications serving hundreds of millions of users. CloudKit uses the Record Layer to host billions of independent databases, many with a common schema.”
Why is the FoundationDB Record Layer used?
The structure of FoundationDB, Record Layer, and CloudKit looks like this:

FoundationDB does all the distributed systems and concurrency control work.
The Record Layer serves as a relational database to make FoundationDB easier to work with.
CloudKit is the highest layer on top and provides features and APIs for application developers. CloudKit isn’t the only thing built on top of the Record Layer, but there are also other layers on top built internally for things that need structured storage, like a JSON document store.
The Record Layer allows Apple to support multi-tenancy at scale.
Actually, that’s somewhat underselling it.
The Record Layer is used for extreme multi-tenancy, where each user of each application gets independent record stores. This means the Record Layer hosts billions of independent databases sharing thousands of schemata.
That’s better! And much, much more impressive.

The Record Layer is engineered to handle multi-tenancy at such a large scale thanks to two fundamental architectural decisions.
The layer operates statelessly allowing for effortless scaling of the compute resources by simply adding more of these stateless instances.
This stateless architecture simplifies the task for load balancers and routers since they only need to focus on the location of the data rather than the capabilities of the compute servers. Additionally, stateless servers have a reduced set of resources to distribute amongst clients.
The layer uses record store abstraction to manage resource allocation and scalability effectively. This abstraction represents the entirety of a logical database, comprising serialized data, indexes, and the operational state.
Each record store is allocated a specific key range, which guarantees logical separation of data for different tenants. Transferring a tenant's data, if necessary, becomes a straightforward process of relocating the assigned key range to a new cluster, as all the information required to manage and use the record store is contained within this range.
This is a good stopping point for a cursory glance of how Apple built iCloud.
For those who are interested in the technical aspects of CloudKit, FoundationDB, and Record Layer, read on.
How CloudKit uses FoundationDB and Record Layer
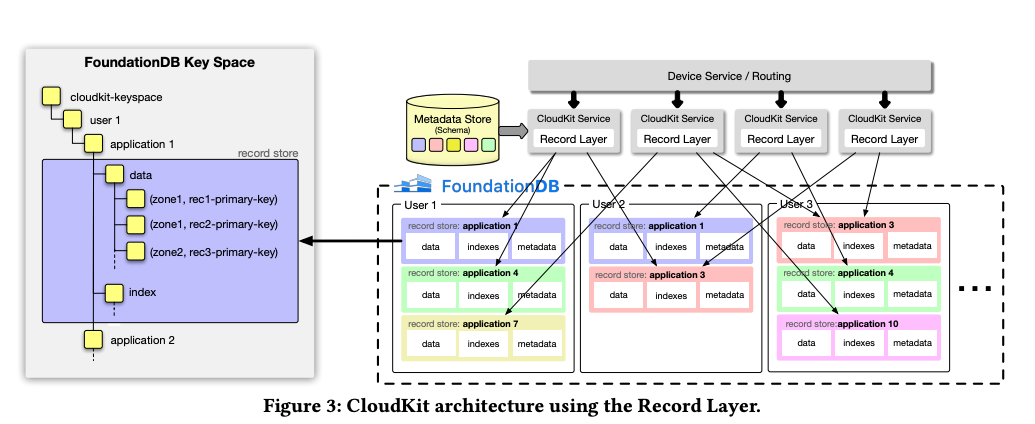
In CloudKit, an application is represented by a 'logical container' which follows a defined schema. This schema outlines the necessary record types, fields, and indexes to enable efficient data retrieval and queries. Applications organize their data into 'zones' within CloudKit, which allows for grouping records logically for selective synchronization with client devices.
For each user, CloudKit designates a unique subspace in FoundationDB. Within this subspace, it creates a record store for each application a user interacts with. In essence, CloudKit manages a massive number of logical databases—multiplying the number of users by the number of applications—each containing its own set of records, indexes, and metadata, amounting to billions of databases.
When CloudKit receives a request from a client device, it directs this request to an available CloudKit Service process via load balancing. This process then interacts with the specific Record Layer record store to fulfill the request.
CloudKit converts the defined application schema into a metadata definition within the Record Layer, which is stored in a separate metadata store. This metadata is augmented by CloudKit-specific system fields that track the record's creation, modification times, and the zone where the record is stored. Zone names are prefixed to primary keys to enable efficient access to records within each zone. Alongside indexes defined by the user, CloudKit also manages 'system indexes' for internal purposes like managing storage quotas by keeping an index that tracks the size of records by their type.
FoundationDB and the Record Layer together solve 4 key problems for Apple that either Cassandra alone or FoundationDB alone could not.
Problem Solved: Personalized full-text search
FoundationDB helps solve personalized full-text search for users to quickly access their data.
Their system utilizes FoundationDB's key order to allow for quick searches on text beginnings (prefix matching) and also for more complex searches (like finding words that are close together or in a specific order - proximity and phrase search) without no extra overhead.
In traditional search systems, you often need extra processes running in the background to keep the search index up to date, but Apple’s system does everything in real-time, which means as soon as data changes, the search index is updated instantly—no extra steps needed.
Problem solved: High-concurrency zones
With FoundationDB, CloudKit handles many updates happening simultaneously in a smooth way.
Previously, with Cassandra, CloudKit used to rely on a special index that kept track of changes in each zone to synchronize data across devices. When a device needed to update its data, it would check this index to see what's new. But this system had a drawback: it could cause conflicts when multiple updates happened at the same time.
But with FoundationDB, CloudKit uses a special kind of index that keeps track of the exact sequence of each change without causing conflicts. This is done by assigning a unique 'version' to every change, and when CloudKit needs to sync, it looks at these versions to figure out what updates a device has missed.
However, when CloudKit needs to move data across different storage clusters—perhaps to distribute the load more evenly—things get tricky because each cluster has its own version numbers that don't match up. To solve this, CloudKit gives each user's data a 'move count' (called the “incarnation”), which increases every time their data is transferred to a new cluster. Each record update includes the user's current “incarnation” number, ensuring that even after a move, CloudKit can still figure out the correct order of updates by looking at both the incarnation and version numbers.
When they switched to this new system, CloudKit faced the challenge of dealing with old data that didn't have these version numbers. They cleverly overcame this by using a special function that sorts old updates using the previous system before the new ones. This meant no complicated changes to the app or leaving behind outdated code. This function took into account the incarnation, version, and the old update-counter values to maintain the correct order of records.
Problem solved: High latency queries
FoundationDB is designed for high-concurrency, not low latency. This means it can handle a lot of tasks at the same time rather than focus on the speed of individual tasks.

To make the most of this design, the Record Layer does a lot of its work 'asynchronously'— it queues up tasks to be completed in the future, allowing for other work to be done in the meantime. This approach helps to cover up any delays that might occur during these tasks.
However, the tool that FoundationDB uses to communicate with its database is designed to do one thing at a time using a single thread for networking. In earlier versions, this setup caused a traffic jam in the system because everything was waiting for its turn in this network thread. The Record Layer had been using this single-threaded approach, which led to a bottleneck.
To improve this, Apple reduced the workload on this network thread. Now, complex tasks seem faster because the system is working with the database on several fronts at the same time, rather than forming a queue. This way, the latency, or the apparent slowness, is hidden because the system doesn't wait for one task to finish before starting another.
Problem solved: Conflicting transactions
In FoundationDB, if one transaction is reading certain keys and another transaction modifies those same keys at the same time, it causes a 'transaction conflict'. FoundationDB allows precise management of these conflicts by providing control over the sets of keys that can cause these conflicts when read or written to.
A common method to avoid unnecessary conflicts is to perform a special kind of read that doesn't cause conflicts, known as a 'snapshot' read, on a range of keys. If this read finds important keys, the transaction will only flag those specific keys for potential conflict, rather than the entire range. This ensures the transaction is only affected by changes that actually matter to its outcome.
The Record Layer uses this strategy to efficiently manage a structure known as a skip list, which is part of its ranking index system. However, manually setting these conflict ranges can be tricky and can lead to bugs that are difficult to identify, especially when they're mixed in with the main logic of the application. Therefore, it's recommended that systems built on top of FoundationDB create higher-level tools, like custom indexes, to handle these patterns. This approach helps to avoid leaving the responsibility to relax conflict rules up to each client application, which could lead to mistakes and inconsistencies.
Thanks for reading! If you’re interested in reading the full FoundationDB Record Layer paper, it’s here: FoundationDB Record Layer: A Multi-Tenant Structured Datastore.
Please add more simplified Diagrams ...Good and a Clean Work.
Nicely written. There is also a white-paper published (slightly old) which provide more details about CloutKit. https://www.vldb.org/pvldb/vol11/p540-shraer.pdf