
Meta's serverless platform processes trillions of function calls a day
XFaaS is Meta's internal platform for "Hyperscale and Low Cost Serverless Functions." They claim its more efficient than AWS Lambda and Azure Functions.
Engineer’s Codex is a newsletter explaining real-world software engineering.
Author’s Note: These are my personal notes of reading the paper regarding Meta’s XFaaS.
Meta’s XFaaS is their serverless platform that “processes trillions of function calls per day on more than 100,000 servers spread across tens of datacenter regions.”1
XFaaS is Meta’s internal version of public Function-as-a-Service (FaaS) options, such as AWS Lambda, Google Cloud Functions, and Azure Functions.
I was lucky enough to get an early look at the paper they wrote about it.
Computer scientists aren’t really the most creative at naming, as there are two papers this year introducing “XFaaS.” One is by Meta, the other by IISC Bangalore scientists.
Both are completely different systems, so if you Google “XFaaS,” just know that this paper is talking about Meta’s version of the system.
In this article, I start off with the high-level takeaways and lessons, for those who want a quick summary. (estimated read time: 3 minutes)
Then, I do a more detailed walkthrough of the paper for those who want to understand the architecture behind XFaaS. (estimated read time: 5 minutes)
Interesting Stats and Takeaways
A key point of the paper is that hardware usage can be optimized by software to improve serverless performance.
Meta recognizes the wastage of startup overhead for serverless functions and aims to emulate a universal worker, i.e., any worker can execute any function instantly without startup overhead.
Hardware costs at scale are huge, and every percentage matters.
XFaaS is only used for non-user-facing functions. Serverless functions have too much variable latency to be consistently used for user-facing functions.
The clients of XFaaS submit function calls in a highly spiky manner. The peak demand is 4.3 times higher than the off-peak demand.
One example of load they demonstrate has 20 million function calls submitted to XFaaS within 15 minutes.
Meta found that even their spiky functions had patterns, which they leveraged to make spiky functions more predictable on their workload.
How efficient is XFaaS?
XFaaS has achieved a daily average CPU utilization of 66%, much better than the industry average.

It efficiently spreads the load using time (by delaying functions) and space (by sending it to a less-loaded datacenter).
Meta is continuing to transition as many of their functions to being scheduled during off-peak hours, where the load and cost is more predictable.
Since it’s an internal cloud, Meta is able to perform a lot of unique optimizations, such as running multiple functions from different users in the same process.
Most functions execute in less than a second, but not all.
SWE Quiz - Lifetime Access to 450+ system design questions
SWE Quiz is a compilation of 450+ software engineering and system design questions covering databases, authentication, caching, etc.
They’ve been created by engineers from Google, Meta, Apple, and more.
It’s helped many of my peers (including myself) pass the “software trivia questions” during interviews and feel more confident at work.
Problems Solved by XFaaS
Problem: Lengthy cold start time.
If a container shuts down too early, the entire container must be initialized again for the next call.
If a container shuts down too late, it sits idle, wasting valuable compute resources.
Solution: XFaaS uses methods like just-in-time compilation to approximate that every worker can instantly execute any function.
Problem: High variance of load.
Results in extra hardware costs due to over-provisioning or in a slower system when under-provisioned
Solution: XFaaS postpones running delay-tolerant functions until off-peak times and distributes function calls worldwide across datacenter regions.
Problem: Overloading downstream services.
Example: Once, a spike in calls from non-user-facing-functions caused an outage for user-facing online services.
Solution: XFaaS employs a mechanism similar to TCP congestion control to regulate the execution of functions.
Comparisons with Public FaaS
Public cloud FaaS confines function executions to a single datacenter region, while XFaaS can dispatch function calls globally, allowing for better load balancing.
FaaS platforms focus on reducing latency first, overlooking hardware utilization. XFaaS focuses on hardware utilization and throughput of function calls.
Lessons for Public FaaS
XFaaS techniques that could benefit public clouds include:
Allowing callers to specify function execution start times.
Enabling function owners to set Service Level Objectives (SLOs) regarding completion deadlines. (Low SLOs can be delayed for a better time.)
Permitting function owners to assign criticality levels to functions.
While public clouds might not run functions from different users in the same process like XFaaS, large cloud customers can adopt the XFaaS approach in their virtual private clouds.
A small number of Meta teams consume a significant portion of XFaaS’s capacity. Similar large customers in public clouds might also benefit from XFaaS’s strategies.
Background: Assumptions and Requirements
This is where the detailed overview of XFaaS begins. Estimated read time: 5 minutes
As mentioned before, XFaaS handles very spikey loads. At peak demand, just one function can receive 1.3 million calls per minute.
Assumptions
A key insight is that most XFaaS functions are triggered by automated workflows, which are okay with delays. Again, this allows XFaaS to balance load across time (by delaying functions) and space (by sending it to a less-loaded datacenter).
XFaaS supports runtimes for PHP, Python, Erlang, Haskell, and a generic container-based runtime for any language.

A function has several attributes that developers can set, such as function name, arguments, runtime, criticality, execution start time, execution completion deadline, resource quota, concurrency limit, and retry policy. The execution completion deadline can range from seconds to 24 hours.
Lastly, XFaaS has varying hardware capacity across regions, so load balancing must take this into account.

Types of Workloads
Meta has three types of workloads on XFaaS: queue-triggered functions, event-triggered functions (from data-change events in data warehouse and data-stream systems), and timer-triggered functions (auto-fired on a pre-set timing).

XFaaS is used for non-user-facing functions, such as async recommendation systems, logging, productivity bots, notifications, and more.
Overall architecture

Clients initiate function calls by sending a request to a submitter, which applies rate limits before passing it to the QueueLB (queue load balancer).
The QueueLB directs the function calls to a DurableQ for storage until completion.
Periodically, the scheduler moves these calls to its FuncBuffer (in-memory function buffer), sorting them by criticality, deadline, and quota.
Ready-to-execute calls move to the RunQ, and the WorkerLB (worker load balancer) then dispatches them to suitable workers.
The submitter, QueueLB, scheduler, and WorkerLB are all stateless, unsharded, and replicated without a designated leader, so their replicas play equal roles.
DurableQ is stateful and has a sharded, highly available database.
Scaling a stateless component is easy by just adding more replicas. If a stateless component fails, it’s work can just be taken over by a peer.
Central Controllers and Fault Tolerance
Central controllers are separate from the function execution path. They continuously optimize the system by updating key configuration parameters, which are consumed by critical-path components like workers and schedulers.

These configs are cached in the components themselves, so if the central controllers fail, the system keeps running just fine (but it cannot be reconfigured).
This allows for central controller downtime for tens of minutes. It’s an example of how Meta has built resilience into this system.
Data Isolation
Functions that require strong isolation for security or performance are assigned to different namespaces, each using distinct worker pools to achieve physical isolation.
Multiple functions can operate in a single Linux process due to trust within a private cloud, mandatory peer reviews, and existing security measures. Data can only flow from lower to higher classification levels.
Submitter
The client sends calls to the submitter. The submitter improves efficiency by batching calls and writing them to DurableQ as one operation.

The submitter manages large argument storage through a distributed key-value store and has built-in rate-limiting policies. To manage the variation in client submission rates, regions have two submitter sets for regular and high-frequency clients.
XFaaS actively monitors high-frequency clients, and human intervention is required for throttling or Service Level Objective (SLO) adjustments.
QueueLB and DurableQ
The submitter then sends function calls to the QueueLB. The Configerator (Configuration Management System central controller) provides routing policies to the QueueLB to balance loads across different regions, as DurableQ hardware capacities vary.
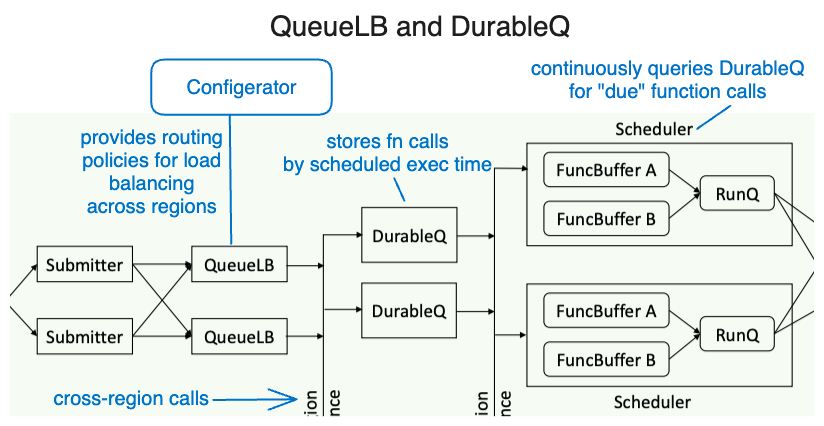
Calls to DurableQs are sharded using UUIDs for equal distribution. Each DurableQ categorizes and stores function calls by their scheduled execution time, set by the caller.
The scheduler continuously queries DurableQs for stored function calls that are due. When a function call is handed over to a scheduler by a DurableQ, it is exclusive to that scheduler unless there's a failure in execution.
The scheduler communicates with the DurableQ:
Sends an ACK message for successful execution. Then the function call is permanently deleted from DurableQ.
NACK for unsuccessful attempts. The function call is made available again in the DurableQ for another scheduler to process.
Scheduler
A scheduler's primary role is to prioritize function calls based on their importance, deadline, and capacity quota.
It fetches function calls from DurableQs, consolidates them into FuncBuffers (ordered by importance, then execution deadline), and then arranges them in a RunQ for execution. Both FuncBuffers and RunQ are in-memory data structures.

To manage efficient execution and prevent system lags, the RunQ controls the flow of function calls. The system also ensures load balancing, with the Global Traffic Conductor (central controller) directing function call traffic across regions based on demand and capacity, optimizing worker utilization across the board.
WorkerLB and Workers

The RunQ from the scheduler sends functions to the WorkerLB (worker load balancer), which has functions run by workers in a worker pool.
In the XFaaS system, functions that use the same programming language have isolation, with a dedicated runtime and worker pool.
The system's design aims to allow immediate function execution by any worker without any initial delays. XFaaS maintains an always-active runtime and keeps functions’ code updated on local SSDs.
Cooperative Just-In-Time (JIT) Compilation to Reduce Overhead
XFaaS introduces cooperative JIT compilation, periodically bundling and pushing function code to workers. Since code is frequently updated, this is necessary.
There are three execution phases to JIT compilation:
A few workers test the new code.
2% of workers further test the code; some perform profiling for JIT compilation.
JIT compilation is done right before receiving function calls, eliminating delays.
With cooperative JIT compilation, a worker reached its maximum requests-per-second in only 3 minutes after a function code update, compared to 21 minutes without JIT compilation.
Locality Groups for Efficient Memory Consumption
Memory constraints make storing every function's JIT code infeasible.
The Locality Optimizer (central controller) partitions functions and workers into groups, ensuring memory-hungry functions are distributed.

Using locality groups reduced memory consumption by 11-12% and allowed for efficient, consistent memory utilization by workers.

How XFaaS Efficiently Handles Load Spikes
Quota for Functions: Every function has a quota, set by its owner, which defines its CPU cycles per second. This quota is transformed into a requests-per-second (RPS) rate limit. The Central Rate Limiter determines whether to throttle function calls based on the function's RPS limit.
Time-Shifting Computing: XFaaS provides reserved (for prompt execution) and opportunistic quotas (for execution within 24 hours during low-demand periods). The Utilization Controller dynamically adjusts the rate of function invocations based on worker utilization.
Dynamic RPS Limits for Functions: To prevent overburdening downstream services, XFaaS utilizes a TCP-like AIMD (Additive Increase, Multiplicative Decrease) method to adjust the RPS limits dynamically. It can set concurrency levels and manage RPS shifts using a slow start approach.
Past challenges, like an XFaaS function overloading the TAO database causing a service cascade failure, highlighted the need for these safeguards. Now, XFaaS has proven its adeptness in shielding downstream services, as seen in real-world incidents where its back-pressure mechanism preemptively curbed potential overloads, ensuring service stability.
My Opinion
This is a fantastic paper. Meta gives us a deep, honest look into their own serverless platform while providing clear lessons for developers and companies who want to optimize their own serverless function usage. The paper can be found here, though you might need institutional access to read it for free.
Furthermore, hardware optimization using software, such as efficient CPU usage, isn’t focused on enough in the industry. It’s not talked about much compared to software optimizations.
In the meantime, if you’re interested in other real-world distributed systems, I also wrote about how Meta handled billions of requests a second by creating the largest Memcached system in the world. Read it here.
If you have any questions about any parts of the paper or system, please do leave a comment below. I will answer them.
Everything here makes sense, great summary. The only question I have concerns the controllers. My understanding is that they are constantly evaluating incoming traffic and then optimizing the system in various ways. I wonder how are these controllers able to compile and process so much data concurrently? I'd be interested in knowing if the paper includes any information about how any of the controllers are able to do this. I'm wondering if it's based on aggregate data being constantly produced into view models, some sort of append only log data, Kafka, or maybe just best effort estimations based on periodic sampling (since at that huge of a scale, sampling could statistically provide decently accurate approximations of the underlying reality)?
> XFaaS has achieved a daily average CPU utilization of 66%, much better than the industry average.
What are the industry averages?
> These configs are cached in the components themselves, so if the central controllers fail, the system keeps running just fine (but it cannot be reconfigured).
I liked all the details about how they made the system resilient. Thanks for writing this article!